![]()
Pandas¶
Comandi base pip packet manager¶
%%capture
# %%capture Nasconde l'output delle instruzioni
# Elencare tutti i pacchetti installati
!pip list
# Mostrare tutti i pacchetti che contengono nel nome la parola "tensorflow"
!pip list | grep tensorflow
# Installare delle librerie specificando il nome
!pip install pandas matplotlib names xlrd openpyxl
# Cercare la libreria (pacchetto) chiamata "names"
!pip search names
# Installare la libreria "names"
!pip install names
# Disinstallare la libreria "names" e controllare che non è installata
!pip uninstall -y names
!pip list | grep names
# Installare la libreria names e controllare che è installata
!pip install names
!pip list | grep names
# Scrivi sul file "requirements.txt" tutte le librie che sto utilizzando
!pip freeze > requirements.txt
%%capture
!pip install pandas
Esempio n.1: Creazione statica di un dataframe¶
In questo primo esempio andremo a creare un dataframe inserendo manualmente il contenuto di ogni colonna. È importate sottolineare che i dataframe in python sono oggetti chiamati dizionari che si basano sulla logica chiave - valore. Infatti per accedere a una colonna (valore) della tabella del nostro dataframe è necessario specificare il nome della colonna (chiave).
Installare e importare la libreria Pandas¶
# Importare la libreria pandas come pd
import pandas as pd
Creazione di un dataframe¶
# Creazione di un Dataframe in cui dati vengono inseriti a mano
# Datafrane (dict-like container for Series Object)
# Each column of a dataframe is a Series
content = {
"Nome" : [
"Amadesi Elena",
"Buscemi Daniela",
"Cantini Nicolò",
"Carta Luca",
"Cortès Rocìo Beatriz",
"Cremonini Gian Marco",
"Crescenzi Francesca",
"Del Magno Saverio",
"Di Tanna Luca",
"Fresu Arianna",
"Hagi Marwa",
"Lesiv Nadiya",
"Losi Lorenzo",
"Magazzino Sara",
"Matti Caterina",
"Mediatore Emanuele",
"Miletta Giorgia",
"Morena Chiara",
"Paladino Emma",
"Peruzzi Orso",
"Pilia Nicola",
"Romano Francesca",
"Rotaru Ilona",
"Tacconi Francesco",
"Teleianu Maria Andreea"
],
"Laurea" : [
"Laurea in Direzione Aziendale",
"Laurea in Lingue Moderne per la cooperazione internazonale",
"Laurea in Relazioni Internazionali",
"Laurea in Geografia e processi territoriali",
"Laurea in Astronomia",
"Laurea in Direzione Aziendale",
"Laurea in Management",
"Laurea in Comunicazione per l'Impresa i Media e le organizzazioni complesse",
"Laurea in Ingegneria Gestionale",
"Laurea in Relazioni Internazionali",
"Laurea in Relazioni Internazionali",
"Laurea in Economia Mercati e Istituzioni",
"Laurea in Ingegneria Ambientale",
"Laurea in Scienze Naturali",
"Laurea in mediazione Linguistica Interculturale",
"Laurea in Giurisprudenza",
"Laurea in Tourism Economics and Management",
"Laurea in Scienze e Tecnologie Agrarie",
"Laurea in Economia e Politica Economica",
"Laurea in Astronomia",
"Laurea in Economia e Gestione delle Imprese",
"Laurea in Ingegneria Elettronica",
"Laurea in Astronomia",
"Laurea in Design del profotto Industriale",
"Laurea in Scienze Statistiche"
],
"PC":
[
"Mac",
"Windows",
"Windows",
"Windows",
"Mac",
"Windows7",
"Windows",
"Mac",
"Windows",
"Mac",
"Mac",
"Mac",
"Windows",
"Windows",
"Windows",
"Windows",
"Windows",
"Windows",
"Windows",
"Windows",
"Windows",
"Windows",
"Windows",
"Windows",
"Windows"
]
}
content2 ={
"Nome": ["Manuel", "Giada", "Marco", "Francesca"],
"Età" : ["26", "25", "28", "29"],
"Sesso": ["M", "F", "M", "F"]
}
df = pd.DataFrame(content) #index=[4,5,6,7] )
#display(df)
df.head()
| Nome | Laurea | PC | |
|---|---|---|---|
| 0 | Amadesi Elena | Laurea in Direzione Aziendale | Mac |
| 1 | Buscemi Daniela | Laurea in Lingue Moderne per la cooperazione i... | Windows |
| 2 | Cantini Nicolò | Laurea in Relazioni Internazionali | Windows |
| 3 | Carta Luca | Laurea in Geografia e processi territoriali | Windows |
| 4 | Cortès Rocìo Beatriz | Laurea in Astronomia | Mac |
Estrarre informazioni sui tipi dati contenuti nella tabella¶
df.dtypes
Nome object
Laurea object
PC object
dtype: object
df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 25 entries, 0 to 24
Data columns (total 3 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Nome 25 non-null object
1 Laurea 25 non-null object
2 PC 25 non-null object
dtypes: object(3)
memory usage: 728.0+ bytes
Estrarre il nome di tutte le colonne¶
df.keys()
for name in df.keys():
print(name)
Nome
Laurea
PC
Estrarre il contenuto dello tabella come array e stampare la dimensione di esso¶
arr = df.values # contenuto della tabella
#display(arr)
print("Dimensione della tabella: ", arr.shape)
print("Valore riga 1, colonna 0: " ,arr[1,0])
Dimensione della tabella: (25, 3)
Valore riga 1, colonna 0: Buscemi Daniela
Creare una nuova tabella chiamata df_small che contiene le prime 4 righe¶
df_small = df.head(4)
df_small
| Nome | Laurea | PC | |
|---|---|---|---|
| 0 | Amadesi Elena | Laurea in Direzione Aziendale | Mac |
| 1 | Buscemi Daniela | Laurea in Lingue Moderne per la cooperazione i... | Windows |
| 2 | Cantini Nicolò | Laurea in Relazioni Internazionali | Windows |
| 3 | Carta Luca | Laurea in Geografia e processi territoriali | Windows |
Creare una nuova tabella chiamata df_small che contiene le ultime 4 righe¶
df_small = df.tail(4)
df_small
| Nome | Laurea | PC | |
|---|---|---|---|
| 21 | Romano Francesca | Laurea in Ingegneria Elettronica | Windows |
| 22 | Rotaru Ilona | Laurea in Astronomia | Windows |
| 23 | Tacconi Francesco | Laurea in Design del profotto Industriale | Windows |
| 24 | Teleianu Maria Andreea | Laurea in Scienze Statistiche | Windows |
Selezionare colonne¶
# Stampare tabella
display(df_small)
# Selezionare colonna Nome
#df_small["Nome"]
# Selezionare colonne Nome e Laurea
display(df_small[["Nome","Laurea"]])
# Selezionare tutte le colonne numero 0 e 2
display(df_small.iloc[:,[0,2]])
# Selezionare da riga 2,a 4 delle colonne numero 0 e 2
display(df_small.iloc[2:4,[0,2]]) # 2:4 è uguale a 2,3
#display(df_small.iloc[[2,3],[0,2]])
| Nome | Laurea | PC | |
|---|---|---|---|
| 21 | Romano Francesca | Laurea in Ingegneria Elettronica | Windows |
| 22 | Rotaru Ilona | Laurea in Astronomia | Windows |
| 23 | Tacconi Francesco | Laurea in Design del profotto Industriale | Windows |
| 24 | Teleianu Maria Andreea | Laurea in Scienze Statistiche | Windows |
| Nome | Laurea | |
|---|---|---|
| 21 | Romano Francesca | Laurea in Ingegneria Elettronica |
| 22 | Rotaru Ilona | Laurea in Astronomia |
| 23 | Tacconi Francesco | Laurea in Design del profotto Industriale |
| 24 | Teleianu Maria Andreea | Laurea in Scienze Statistiche |
| Nome | PC | |
|---|---|---|
| 21 | Romano Francesca | Windows |
| 22 | Rotaru Ilona | Windows |
| 23 | Tacconi Francesco | Windows |
| 24 | Teleianu Maria Andreea | Windows |
| Nome | PC | |
|---|---|---|
| 23 | Tacconi Francesco | Windows |
| 24 | Teleianu Maria Andreea | Windows |
Selezionare righe¶
# Stampare tabella
display(df_small)
# Selezionare i valori nella Riga 1 e colonne 0 e 2
display(df_small.iloc[[1],[0,2]])
# Selezionare tutta le righe 0 e 3
display(df_small.iloc[[0,3],:])
#df_small.iloc[[0,3]]
| Nome | Laurea | PC | |
|---|---|---|---|
| 21 | Romano Francesca | Laurea in Ingegneria Elettronica | Windows |
| 22 | Rotaru Ilona | Laurea in Astronomia | Windows |
| 23 | Tacconi Francesco | Laurea in Design del profotto Industriale | Windows |
| 24 | Teleianu Maria Andreea | Laurea in Scienze Statistiche | Windows |
| Nome | PC | |
|---|---|---|
| 22 | Rotaru Ilona | Windows |
| Nome | Laurea | PC | |
|---|---|---|---|
| 21 | Romano Francesca | Laurea in Ingegneria Elettronica | Windows |
| 24 | Teleianu Maria Andreea | Laurea in Scienze Statistiche | Windows |
Aggiungere una nuova colonna¶
#df_small['Età'] = [26,27,28,26]
df_small.insert(3, "Età", [26, 27, 28, 26])
#df_small = df_small.assign(eta = [26, 27, 28, 26])
df_small
| Nome | Laurea | PC | Età | |
|---|---|---|---|---|
| 21 | Romano Francesca | Laurea in Ingegneria Elettronica | Windows | 26 |
| 22 | Rotaru Ilona | Laurea in Astronomia | Windows | 27 |
| 23 | Tacconi Francesco | Laurea in Design del profotto Industriale | Windows | 28 |
| 24 | Teleianu Maria Andreea | Laurea in Scienze Statistiche | Windows | 26 |
Rimuovere colonne¶
#df_small.drop(['Laurea', 'Sesso'], axis=1)
#df_small_new = df_small.drop(columns=['PC', 'Età']) # inplace=True) # inplace permetter l'assegmamento automatico
df_small.drop(columns=['PC', 'Età'])
| Nome | Laurea | |
|---|---|---|
| 21 | Romano Francesca | Laurea in Ingegneria Elettronica |
| 22 | Rotaru Ilona | Laurea in Astronomia |
| 23 | Tacconi Francesco | Laurea in Design del profotto Industriale |
| 24 | Teleianu Maria Andreea | Laurea in Scienze Statistiche |
Rimuovere righe¶
# rimuove riga 23 e 24 (in base all'enumerazione dell indice)
df_small.drop([23, 24]) # inplace=True)
| Nome | Laurea | PC | Età | |
|---|---|---|---|---|
| 21 | Romano Francesca | Laurea in Ingegneria Elettronica | Windows | 26 |
| 22 | Rotaru Ilona | Laurea in Astronomia | Windows | 27 |
Ordinare una tabella¶
# Facciamo un display della tabella iniziale
df_small
# display(df_small)
# print(df_small)
| Nome | Laurea | PC | Età | |
|---|---|---|---|---|
| 21 | Romano Francesca | Laurea in Ingegneria Elettronica | Windows | 26 |
| 22 | Rotaru Ilona | Laurea in Astronomia | Windows | 27 |
| 23 | Tacconi Francesco | Laurea in Design del profotto Industriale | Windows | 28 |
| 24 | Teleianu Maria Andreea | Laurea in Scienze Statistiche | Windows | 26 |
# Ordinamento della tabella guardando alla colonna Età dal piu piccolo al piu grande
df_sorted = df_small.sort_values(by="Età", ascending=True)
display(df_sorted.head())
| Nome | Laurea | PC | Età | |
|---|---|---|---|---|
| 21 | Romano Francesca | Laurea in Ingegneria Elettronica | Windows | 26 |
| 24 | Teleianu Maria Andreea | Laurea in Scienze Statistiche | Windows | 26 |
| 22 | Rotaru Ilona | Laurea in Astronomia | Windows | 27 |
| 23 | Tacconi Francesco | Laurea in Design del profotto Industriale | Windows | 28 |
Resettare gli indici (righe) della tabella¶
# Reset dell indice da 0 a N
df_sorted = df_sorted.reset_index()
display(df_sorted.head())
| index | Nome | Laurea | PC | Età | |
|---|---|---|---|---|---|
| 0 | 21 | Romano Francesca | Laurea in Ingegneria Elettronica | Windows | 26 |
| 1 | 24 | Teleianu Maria Andreea | Laurea in Scienze Statistiche | Windows | 26 |
| 2 | 22 | Rotaru Ilona | Laurea in Astronomia | Windows | 27 |
| 3 | 23 | Tacconi Francesco | Laurea in Design del profotto Industriale | Windows | 28 |
Esempio n.2 : Creazione dinamica di un dataframe¶
In questo esempio andremo a creare programmaticamente (usando codice python) un dataframe. Per fare ciñ utilizzeremo la libreria names che genera randomicamente dei nomi e dei cognomi.
Installare e importare le librerie¶
%%capture
# installare le librerie names e numpy
!pip install names numpy pandas
# Importare le librerie
import names
import numpy as np
import pandas as pd
Creare una lista di nomi,di cognomi ed età in modo automatico¶
# Creare una lista di nomi,di cognomi ed età in modo automatico
list_names = []
list_surnames = []
list_nums = []
for i in range(0,30):
num = np.random.randint(20,30,1)[0]
#name = names.get_full_name()
name = names.get_first_name()
surname = names.get_last_name()
#list_names.append([name, surname])
list_names.append(name)
list_surnames.append(surname)
list_nums.append(num)
#display(name)
print(list_names)
print("--------")
print("--------")
print(list_surnames)
print("--------")
print("--------")
print(list_nums)
['Lawrence', 'Michael', 'Lauren', 'Mary', 'Jean', 'Pamela', 'Sara', 'Freddie', 'Brandie', 'Kathleen', 'William', 'Susan', 'Dustin', 'Charles', 'Candy', 'Randall', 'William', 'Heather', 'Ralph', 'Molly', 'Len', 'Claude', 'Robert', 'Kimberly', 'Maurice', 'Megan', 'Betty', 'Mary', 'Stephanie', 'James']
--------
--------
['Ortiz', 'Lackey', 'Cole', 'Wiley', 'Eby', 'Mills', 'Lund', 'Shiels', 'Greenfield', 'Steiner', 'Mitchell', 'Arnold', 'Terry', 'Mcclain', 'Thompson', 'Dunston', 'Harbison', 'Taylor', 'Dick', 'Fortman', 'Vess', 'Brown', 'Blazek', 'Zimmerman', 'Jones', 'Curran', 'Reed', 'Pedro', 'Tryon', 'Couch']
--------
--------
[20, 27, 27, 27, 29, 24, 25, 25, 22, 22, 25, 24, 22, 27, 20, 26, 23, 29, 22, 28, 23, 26, 23, 22, 29, 26, 21, 21, 24, 29]
Creare un dataframe da delle liste¶
# Datafrane (dict-like container for Series Object)
content = {
"Nome": list_names,
"Cognomi": list_surnames,
"Età" : list_nums
}
dff = pd.DataFrame(content )
# Mostrare l'intero dataframe
#display(df)
# Stampare le prime 5 righe
#display(dff.head())
# Stampare le ultime
display(df.tail())
| Nome | Laurea | PC | |
|---|---|---|---|
| 20 | Pilia Nicola | Laurea in Economia e Gestione delle Imprese | Windows |
| 21 | Romano Francesca | Laurea in Ingegneria Elettronica | Windows |
| 22 | Rotaru Ilona | Laurea in Astronomia | Windows |
| 23 | Tacconi Francesco | Laurea in Design del profotto Industriale | Windows |
| 24 | Teleianu Maria Andreea | Laurea in Scienze Statistiche | Windows |
Ordinare i dati in base all’età dal più grande al più piccolo e mostrare le prime 8 righe¶
display(dff.sort_values(by="Età", ascending=False).head(8))
| Nome | Cognomi | Età | |
|---|---|---|---|
| 29 | James | Couch | 29 |
| 4 | Jean | Eby | 29 |
| 24 | Maurice | Jones | 29 |
| 17 | Heather | Taylor | 29 |
| 19 | Molly | Fortman | 28 |
| 13 | Charles | Mcclain | 27 |
| 2 | Lauren | Cole | 27 |
| 3 | Mary | Wiley | 27 |
Della colonna Età selezione i valori che banno da riga 0 a 3¶
# Da notare che 0:4 seleziona le righe da 0,1,2,3
dff["Età"][0:4]
0 20
1 27
2 27
3 27
Name: Età, dtype: int64
Della colonna Età e Cognomi seleziona i valori che banno da riga 0 a 3¶
dff[["Età","Cognomi"]][0:4]
| Età | Cognomi | |
|---|---|---|
| 0 | 20 | Ortiz |
| 1 | 27 | Lackey |
| 2 | 27 | Cole |
| 3 | 27 | Wiley |
Della colonna età selezionare tutte le righe che hanno età=20¶
dff[dff["Età"]==20]
| Nome | Cognomi | Età | |
|---|---|---|---|
| 0 | Lawrence | Ortiz | 20 |
| 14 | Candy | Thompson | 20 |
Della colonna età selezionare tutte le righe che hanno età tra 20 (escluso) e 24 (incluso)¶
dff[(dff["Età"]>20) & (dff["Età"]<=24)]
#dff.loc[(dff["Età"]>20) & (dff["Età"]<=24)]
| Nome | Cognomi | Età | |
|---|---|---|---|
| 5 | Pamela | Mills | 24 |
| 8 | Brandie | Greenfield | 22 |
| 9 | Kathleen | Steiner | 22 |
| 11 | Susan | Arnold | 24 |
| 12 | Dustin | Terry | 22 |
| 16 | William | Harbison | 23 |
| 18 | Ralph | Dick | 22 |
| 20 | Len | Vess | 23 |
| 22 | Robert | Blazek | 23 |
| 23 | Kimberly | Zimmerman | 22 |
| 26 | Betty | Reed | 21 |
| 27 | Mary | Pedro | 21 |
| 28 | Stephanie | Tryon | 24 |
Delle colonne Nome e Cognomi trova tutti i Nomi che hanno la lettera D o M mauscole¶
dff[dff["Nome"].str.contains("D|M") | dff["Cognomi"].str.contains("D|M")]
| Nome | Cognomi | Età | |
|---|---|---|---|
| 1 | Michael | Lackey | 27 |
| 3 | Mary | Wiley | 27 |
| 5 | Pamela | Mills | 24 |
| 10 | William | Mitchell | 25 |
| 12 | Dustin | Terry | 22 |
| 13 | Charles | Mcclain | 27 |
| 15 | Randall | Dunston | 26 |
| 18 | Ralph | Dick | 22 |
| 19 | Molly | Fortman | 28 |
| 24 | Maurice | Jones | 29 |
| 25 | Megan | Curran | 26 |
| 27 | Mary | Pedro | 21 |
Sostituire nella colonna Nome “e” con “,AAAA” (Replace method)¶
dff["Nome"] = dff["Nome"].str.replace("e",",AAAA")
# Mostra solo le prime 3 righe
dff.head(3)
| Nome | Cognomi | Età | |
|---|---|---|---|
| 0 | Lawr,AAAAnc,AAAA | Ortiz | 20 |
| 1 | Micha,AAAAl | Lackey | 27 |
| 2 | Laur,AAAAn | Cole | 27 |
# Viceversa: Sostituire ",AAAA" con "e"
dff["Nome"] = dff["Nome"].str.replace(",AAAA","e")
# Mostra solo le prime 5 righe
dff.head(3)
| Nome | Cognomi | Età | |
|---|---|---|---|
| 0 | Lawrence | Ortiz | 20 |
| 1 | Michael | Lackey | 27 |
| 2 | Lauren | Cole | 27 |
Esempio n.3: Creazione di un dataframe usando csv e fogli excel¶
Importare dataset da url online¶
# Dataset mondo covid 19
data = pd.read_csv('https://open-covid-19.github.io/data/data.csv')
data
| Date | Key | CountryCode | CountryName | RegionCode | RegionName | Confirmed | Deaths | Latitude | Longitude | Population | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2019-12-30 | AE | AE | United Arab Emirates | NaN | NaN | 0.0 | 0.0 | 24.400000 | 54.300000 | 9.400145e+06 |
| 1 | 2019-12-30 | AF | AF | Afghanistan | NaN | NaN | 0.0 | 0.0 | 34.000000 | 66.000000 | 3.494084e+07 |
| 2 | 2019-12-30 | AM | AM | Armenia | NaN | NaN | 0.0 | 0.0 | 40.383333 | 44.950000 | 2.930450e+06 |
| 3 | 2019-12-30 | AT | AT | Austria | NaN | NaN | 0.0 | 0.0 | 48.000000 | 14.000000 | 8.809212e+06 |
| 4 | 2019-12-30 | AU | AU | Australia | NaN | NaN | 0.0 | 0.0 | -28.000000 | 137.000000 | 2.451180e+07 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 67074 | 2020-05-26 | UA_40 | RU | Russia | 40 | Sevastopol | 158.0 | NaN | 44.600000 | 33.533333 | 4.488290e+05 |
| 67075 | 2020-05-26 | UA_43 | RU | Russia | 43 | Republic of Crimea | 346.0 | NaN | 44.933300 | 34.100000 | 1.957801e+06 |
| 67076 | 2020-05-26 | XK | XK | Kosovo | NaN | NaN | 1038.0 | 30.0 | 42.550000 | 20.833333 | 1.883018e+06 |
| 67077 | 2020-05-27 | CN | CN | China | NaN | NaN | 84543.0 | 4645.0 | 35.000000 | 103.000000 | 1.382793e+09 |
| 67078 | 2020-05-27 | CN_HK | CN | China | HK | Hong Kong | 1065.0 | 4.0 | 22.278333 | 114.158610 | 7.500700e+06 |
67079 rows × 11 columns
# Dataset mondo covid 19
dati_province = "https://raw.githubusercontent.com/pcm-dpc/COVID-19/master/dati-province/dpc-covid19-ita-province.csv"
dati_regioni = "https://raw.githubusercontent.com/pcm-dpc/COVID-19/master/dati-regioni/dpc-covid19-ita-regioni.csv"
dati_italia = "https://raw.githubusercontent.com/pcm-dpc/COVID-19/master/dati-andamento-nazionale/dpc-covid19-ita-andamento-nazionale.csv"
data = pd.read_csv(dati_italia)
display(data.head(5))
| data | stato | ricoverati_con_sintomi | terapia_intensiva | totale_ospedalizzati | isolamento_domiciliare | totale_positivi | variazione_totale_positivi | nuovi_positivi | dimessi_guariti | deceduti | totale_casi | tamponi | casi_testati | note_it | note_en | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2020-02-24T18:00:00 | ITA | 101 | 26 | 127 | 94 | 221 | 0 | 221 | 1 | 7 | 229 | 4324 | NaN | NaN | NaN |
| 1 | 2020-02-25T18:00:00 | ITA | 114 | 35 | 150 | 162 | 311 | 90 | 93 | 1 | 10 | 322 | 8623 | NaN | NaN | NaN |
| 2 | 2020-02-26T18:00:00 | ITA | 128 | 36 | 164 | 221 | 385 | 74 | 78 | 3 | 12 | 400 | 9587 | NaN | NaN | NaN |
| 3 | 2020-02-27T18:00:00 | ITA | 248 | 56 | 304 | 284 | 588 | 203 | 250 | 45 | 17 | 650 | 12014 | NaN | NaN | NaN |
| 4 | 2020-02-28T18:00:00 | ITA | 345 | 64 | 409 | 412 | 821 | 233 | 238 | 46 | 21 | 888 | 15695 | NaN | NaN | NaN |
Stampare i tipi di dati contenuti nel dataframe¶
display(data.info())
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 93 entries, 0 to 92
Data columns (total 16 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 data 93 non-null object
1 stato 93 non-null object
2 ricoverati_con_sintomi 93 non-null int64
3 terapia_intensiva 93 non-null int64
4 totale_ospedalizzati 93 non-null int64
5 isolamento_domiciliare 93 non-null int64
6 totale_positivi 93 non-null int64
7 variazione_totale_positivi 93 non-null int64
8 nuovi_positivi 93 non-null int64
9 dimessi_guariti 93 non-null int64
10 deceduti 93 non-null int64
11 totale_casi 93 non-null int64
12 tamponi 93 non-null int64
13 casi_testati 38 non-null float64
14 note_it 29 non-null object
15 note_en 29 non-null object
dtypes: float64(1), int64(11), object(4)
memory usage: 11.8+ KB
None
Esportare il dataframe come foglio excel¶
data.to_excel('dati_italia.xlsx', index=False)
Esportare il dataframe come csv¶
data.to_csv('dati_italia.csv', index=False)
Importare un excel in un dataframe¶
data = pd.read_excel('dati_italia.xlsx')
data.head()
# Su colab è possibile caricare file: Upload option
| data | stato | ricoverati_con_sintomi | terapia_intensiva | totale_ospedalizzati | isolamento_domiciliare | totale_positivi | variazione_totale_positivi | nuovi_positivi | dimessi_guariti | deceduti | totale_casi | tamponi | casi_testati | note_it | note_en | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2020-02-24T18:00:00 | ITA | 101 | 26 | 127 | 94 | 221 | 0 | 221 | 1 | 7 | 229 | 4324 | NaN | NaN | NaN |
| 1 | 2020-02-25T18:00:00 | ITA | 114 | 35 | 150 | 162 | 311 | 90 | 93 | 1 | 10 | 322 | 8623 | NaN | NaN | NaN |
| 2 | 2020-02-26T18:00:00 | ITA | 128 | 36 | 164 | 221 | 385 | 74 | 78 | 3 | 12 | 400 | 9587 | NaN | NaN | NaN |
| 3 | 2020-02-27T18:00:00 | ITA | 248 | 56 | 304 | 284 | 588 | 203 | 250 | 45 | 17 | 650 | 12014 | NaN | NaN | NaN |
| 4 | 2020-02-28T18:00:00 | ITA | 345 | 64 | 409 | 412 | 821 | 233 | 238 | 46 | 21 | 888 | 15695 | NaN | NaN | NaN |
Visualizzare la colonna di terapia_intensiva come riga¶
# Creare un nuovo dataframe contenente le colonne data e terapia_intensiva
dn = data[["data", "terapia_intensiva"]]
#display(dn.shape)
# Eseguire l'operazione Trasposta. Che inverte righe con colonne
dn = dn.T
display(dn)
#display(dn.shape)
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | ... | 83 | 84 | 85 | 86 | 87 | 88 | 89 | 90 | 91 | 92 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| data | 2020-02-24T18:00:00 | 2020-02-25T18:00:00 | 2020-02-26T18:00:00 | 2020-02-27T18:00:00 | 2020-02-28T18:00:00 | 2020-02-29T18:00:00 | 2020-03-01T18:00:00 | 2020-03-02T18:00:00 | 2020-03-03T18:00:00 | 2020-03-04T18:00:00 | ... | 2020-05-17T17:00:00 | 2020-05-18T17:00:00 | 2020-05-19T17:00:00 | 2020-05-20T17:00:00 | 2020-05-21T17:00:00 | 2020-05-22T17:00:00 | 2020-05-23T17:00:00 | 2020-05-24T17:00:00 | 2020-05-25T17:00:00 | 2020-05-26T17:00:00 |
| terapia_intensiva | 26 | 35 | 36 | 56 | 64 | 105 | 140 | 166 | 229 | 295 | ... | 762 | 749 | 716 | 676 | 640 | 595 | 572 | 553 | 541 | 521 |
2 rows × 93 columns
Mostrare gli utimi 10 risultati¶
# Vogliamo le ultime 5 date o le prime 5 date
dn = data[["data", "terapia_intensiva","isolamento_domiciliare", "ricoverati_con_sintomi"]]
display(dn.tail(10)) # ultimi 10
#display(dn.iloc[-10:,:]) # ultimi 10
| data | terapia_intensiva | isolamento_domiciliare | ricoverati_con_sintomi | |
|---|---|---|---|---|
| 83 | 2020-05-17T17:00:00 | 762 | 57278 | 10311 |
| 84 | 2020-05-18T17:00:00 | 749 | 55597 | 10207 |
| 85 | 2020-05-19T17:00:00 | 716 | 54422 | 9991 |
| 86 | 2020-05-20T17:00:00 | 676 | 52452 | 9624 |
| 87 | 2020-05-21T17:00:00 | 640 | 51051 | 9269 |
| 88 | 2020-05-22T17:00:00 | 595 | 49770 | 8957 |
| 89 | 2020-05-23T17:00:00 | 572 | 48485 | 8695 |
| 90 | 2020-05-24T17:00:00 | 553 | 47428 | 8613 |
| 91 | 2020-05-25T17:00:00 | 541 | 46574 | 8185 |
| 92 | 2020-05-26T17:00:00 | 521 | 44504 | 7917 |
Filtrare la colonna “ricoverati_con_sintomi” tenendo solo valori > 100¶
# Select specific rows columns
sel = dn.loc[data["ricoverati_con_sintomi"]>100]
#sel = dn.loc[data["ricoverati_con_sintomi"]>100, "isolamento_domiciliare"]
#display(sel)
Selezionare le colonne “data” e “isolamento_domiciliare” e mostrare solo i dati relativi alla data=”2020-03-19T17:00:00”¶
# Select specific row columns (da a (data specifica))
#2020-03-19T17:00:00
#2020-03-25T17:00:00
# index[0] This will return the index of the first row of the result...
dn = data[["data", "terapia_intensiva","isolamento_domiciliare", "ricoverati_con_sintomi"]]
idxstart = dn[dn["data"]=="2020-03-19T17:00:00"].index[0]
idxstop = dn[dn["data"]=="2020-03-25T17:00:00"].index[0]
#print(idxstart,idxstop)
#dn = dn.iloc[idxstart:idxstop,:] # row da data scelta start a data scelta stop, colonne tutte
#dn = dn.iloc[idxstart:idxstop,:-1] # -1 rimuove la colonna
#dn = dn.iloc[idxstart:idxstop,2:4] # 4 colonne
dn = dn.iloc[idxstart:idxstop,[0,2]] # 4 colonne
dn
| data | isolamento_domiciliare | |
|---|---|---|
| 24 | 2020-03-19T17:00:00 | 14935 |
| 25 | 2020-03-20T17:00:00 | 19185 |
| 26 | 2020-03-21T17:00:00 | 22116 |
| 27 | 2020-03-22T17:00:00 | 23783 |
| 28 | 2020-03-23T17:00:00 | 26522 |
| 29 | 2020-03-24T17:00:00 | 28697 |
Grafici usando pandas¶
dn = data[["data", "totale_casi", "deceduti","totale_positivi"]]
display(dn.head())
| data | totale_casi | deceduti | totale_positivi | |
|---|---|---|---|---|
| 0 | 2020-02-24T18:00:00 | 229 | 7 | 221 |
| 1 | 2020-02-25T18:00:00 | 322 | 10 | 311 |
| 2 | 2020-02-26T18:00:00 | 400 | 12 | 385 |
| 3 | 2020-02-27T18:00:00 | 650 | 17 | 588 |
| 4 | 2020-02-28T18:00:00 | 888 | 21 | 821 |
# Problema: datetime deve essere tutta una parola
#dn["data"] = pd.to_datetime(data["data"])
#display(dn.head(4))
#display(dn.dtypes)
from matplotlib import pyplot as plt
plt.style.use('seaborn') # fivethirtyeight
fig, ax = plt.subplots(1, 1, figsize=(18,8))
dn.plot(kind="bar",stacked=True,ax=ax)
<matplotlib.axes._subplots.AxesSubplot at 0x7f94c2c09ef0>

fig, ax = plt.subplots(1, 1, figsize=(18,8))
dn.plot(kind="bar",stacked=False,ax=ax)
<matplotlib.axes._subplots.AxesSubplot at 0x7f94c1dbdf28>
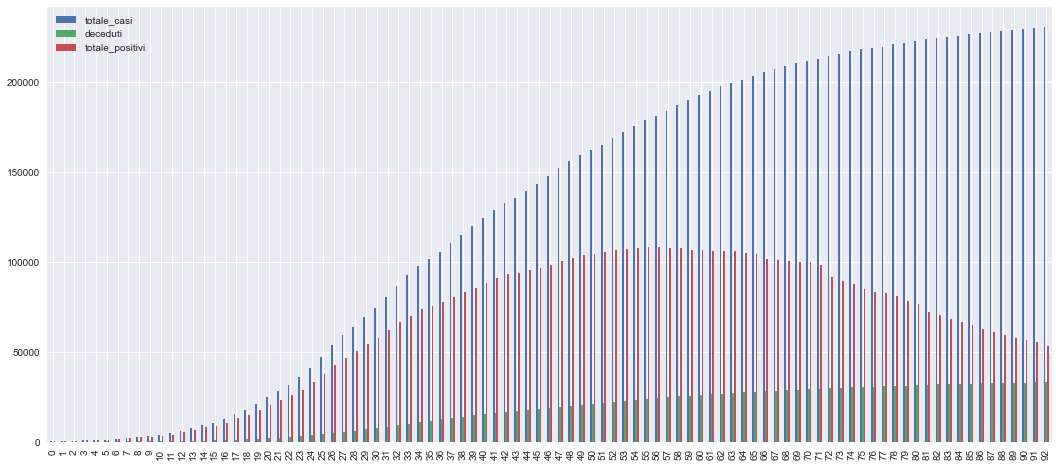
fig, ax = plt.subplots(1, 1, figsize=(18,8))
dn.plot(kind="line",stacked=False,ax=ax )
#dn.plot(kind="area", stacked=False,ax=ax )
<matplotlib.axes._subplots.AxesSubplot at 0x7f94c19ff2e8>
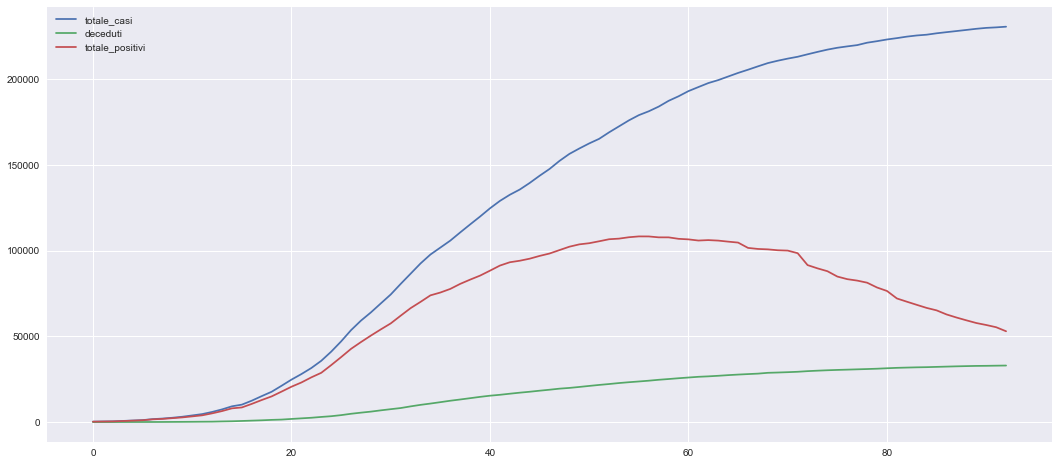
dfin = dn.tail(1)
dfin = dfin.drop(columns="data")
dfin
| totale_casi | deceduti | totale_positivi | |
|---|---|---|---|
| 92 | 230555 | 32955 | 52942 |
#list(dfin.columns)
list(dfin.iloc[0,:])
list(dfin.values[0])
[230555, 32955, 52942]
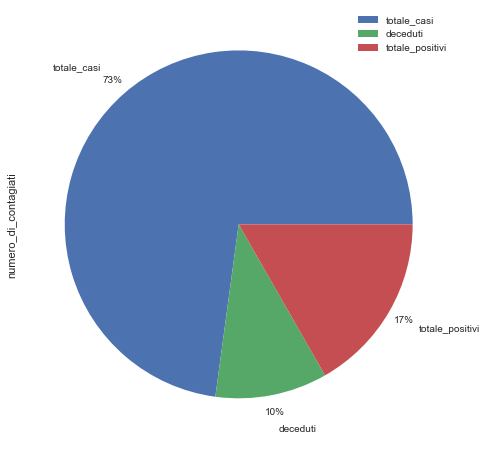
d = {
'numero_di_contagiati': list(dfin.values[0])
}
dpie = pd.DataFrame(d,index= list(dfin.columns))
dpie
| numero_di_contagiati | |
|---|---|
| totale_casi | 230555 |
| deceduti | 32955 |
| totale_positivi | 52942 |
fig, ax = plt.subplots(1, 1, figsize=(18,8))
dpie.plot(kind="pie", y="numero_di_contagiati",ax=ax,autopct='%1.0f%%', pctdistance=1.1, labeldistance=1.2)
fig.savefig("covid19.png")
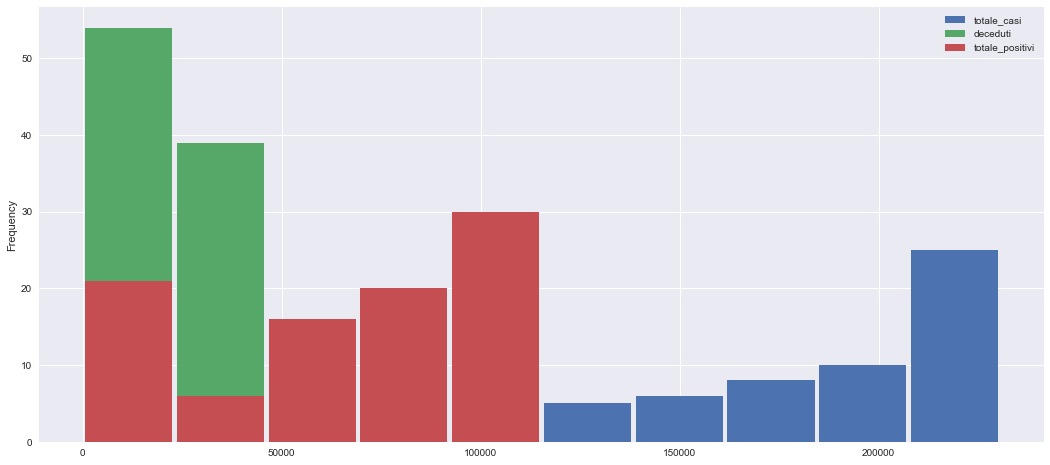
fig, ax = plt.subplots(1, 1, figsize=(18,8))
dn.plot(kind="hist",ax=ax,bins=10,rwidth=0.95)
<matplotlib.axes._subplots.AxesSubplot at 0x7f94c189b048>
Grafici usando Matplotlib¶
from matplotlib import pyplot as plt
# Set the style globally
# Alternatives include bmh, fivethirtyeight, ggplot,dark_background
# dark_background, seaborn-deep, etc
#plt.style.use('fivethirtyeight')
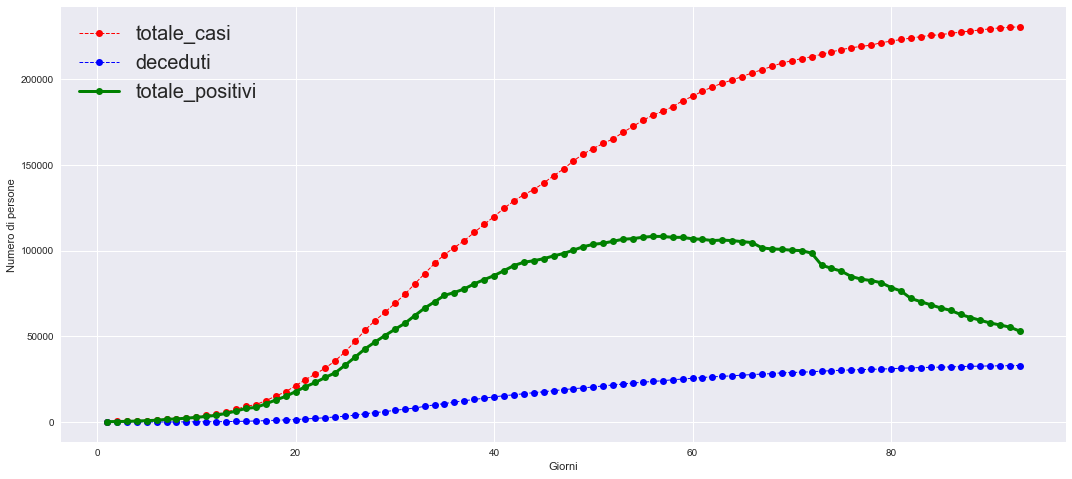
plt.figure(figsize=(18,8))
#plt.plot(dn["data"], dn.iloc[:,1])
idx = np.linspace(1,len(data["data"]),len(data["data"]))
plt.plot(idx,data["totale_casi"],'ro--',label="totale_casi", linewidth=1)
plt.plot(idx,data["deceduti"],'bo--',label="deceduti", linewidth=1)
plt.plot(idx,data["totale_positivi"],'go-',label="totale_positivi", linewidth=3)
plt.legend( prop={'size': 20})
plt.ylabel("Numero di persone")
plt.xlabel("Giorni")
#plt.grid()
plt.show()
Plotly dash¶
import plotly.graph_objects as go
# https://plotly.com/python/line-charts/
# lines, markers, line+martkers
# https://plotly.com/python/creating-and-updating-figures/
# https://plotly.com/python/reference/#layout-title
fig = go.Figure()
fig.add_trace(go.Scatter(x=data["data"], y=data["totale_casi"],
mode='lines+markers',
name='totale_casi'))
fig.add_trace(go.Scatter(x=data["data"], y=data["deceduti"],
mode='lines+markers',
name='deceduti'))
fig.add_trace(go.Scatter(x=data["data"], y=data["totale_positivi"],
mode='lines+markers',
name='totale_positivi'))
fig.layout.hovermode = "x" #['x', 'y', 'closest', False]
fig.layout.paper_bgcolor = "rgb(0,0,0)"
fig.layout.font.size = 20
fig.layout.title.text = "Andamento Italia COVID 19"
fig.layout.title.x = 0.5
fig.layout.titlefont.size = 40
fig.layout.title.font.color = "rgb(255,255,255)"
fig.layout.plot_bgcolor = "rgb(10,10,10)"
fig.show()